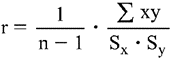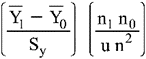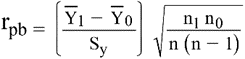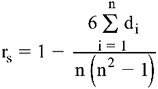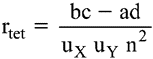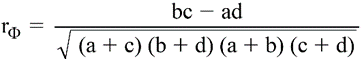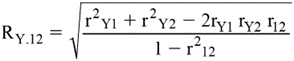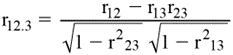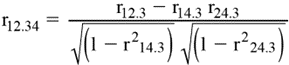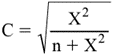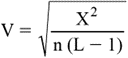Rech./Stat. Statistique indiquant le degré d’association ou de relation entre deux ou plusieurs variables au sein d’un même groupe de sujets. EA recherche corrélationnelle.
A. Signification. Une absence de relation ou d’association est indiquée par un coefficient de valeur 0. Une corrélation parfaite est indiquée par un coefficient de valeur 1 (ce maximum est moindre lorsque les variables mises en relation sont dichotomiques ou lorsque au moins l’une des variables est nominalement dichotomique). Un coefficient de corrélation peut être négatif lorsque les variables concernées sont en relation inverse (les valeurs de l’une décroissent pendant que croissent les valeurs de l’autre). Toutefois, les coefficients sont toujours positifs lorsqu’ils sont calculés comme résultant d’une extraction de racine carrée au numérateur de la formule utilisée. L’échelle suivante (GUILFORD, J. P., 1965) est souvent utilisée pour interpréter l’intensité de la corrélation selon la valeur absolue du coefficient.
Toutefois, une corrélation peut être forte, mais non significative si elle a été obtenue avec un très petit nombre de sujets; ou elle peut être faible, mais statistiquement significative si elle a été obtenue au sein d’un très grand nombre de sujets.
B. Pluralité. Il existe différents coefficients de corrélation simple entre deux variables mises en corrélation, dépendant des types d’échelles de mesure utilisées pour décrire ces deux variables :
Selon le tableau précédent, une dizaine de coefficients de corrélation simple peuvent exister (car rxy = ryx) dont huit sont présentés et discutés ci-après parce qu’ils représentent les cas les plus courants dans le domaine de l’éducation. Les quatre cas non discutés peuvent être étudiés en utilisant des ouvrages spécialisés. En outre, lorsque plus de deux variables sont mises en corrélation, d’autres coefficients doivent alors être calculés (VA I, J et K).
C. Coefficient de Bravais-Pearson : méthode classique de calcul du degré de relation linéaire entre deux variables continues.
où : x : écart entre les scores de la variable X et leur moyenne
y : écart entre les scores de la variable Y et leur moyenne
n : nombre de sujets
Sx : écart type de x pour les n sujets
Sy : écart type de y pour les n sujets
2. Exemple : Un enseignant veut savoir s’il existe une corrélation significative entre le nombre d’heures que les élèves de 4e année de son école consacrent à l’étude personnelle et leur rendement scolaire. Il choisit un échantillon aléatoire de trente-deux élèves de 4e année et pour chaque élève, il associe le nombre d’heures moyen alloué par semaine à l’étude et le score moyen obtenu pour l’ensemble des cours. En utilisant la formule de Bravais-Pearson, il obtient :
r = + 0,40 (corrélation positive)
3. Interprétation : L’enseignant doit vérifier si cette valeur de « r », indiquant une corrélation modérée, est statistiquement significative ou si elle n’est pas tout simplement le fruit du hasard. En consultant la table des valeurs critiques de r, il constate que pour n = 32 et α = 0,05 (seuil de signification), le « r critique » vaut 0,30, pour un test unilatéral. Puisque (r calculé = 0,40) > (r critique = 0,30), l’enseignant est amené à conclure qu’il existe une corrélation statistiquement significative au seuil de 0,05 entre le nombre d’heures d’étude de ses élèves et leur rendement scolaire. Plus le nombre d’heures d’étude est élevé, meilleur est le rendement scolaire. L’enseignant doit admettre que cette corrélation est modérée en regard de l’échelle (GUILFORD, J. P., 1965) pour interpréter l’intensité de la corrélation selon la valeur absolue du coefficient. VA A.
D. Coefficient de corrélation bisériale : coefficient qui mesure le degré de relation linéaire entre une variable continue (Y) et une variable artificiellement dichotomique (X).
où : Y1 = moyenne à Y de ceux qui ont obtenu le score 1 à X
Y0 = moyenne à Y de ceux qui ont obtenu le score 0 à X
Sy = écart type de Y pour les n sujets
n1 = nombre de sujets qui ont obtenu 1 à la variable X
n0 = nombre de sujets qui ont obtenu 0 à la variable X
n = nombre total de sujets = n1 + n 0
u = ordonnée de la distribution normale centrée réduite à p (selon table appropriée)
p = proportion de personnes ayant obtenu 1 à la variable X (p = n1/n)
2. Exemple : Considérer l’exemple donné en C. Ici, l’enseignant veut savoir s’il existe une corrélation significative entre le rendement scolaire (variable continue) et la performance à un item de mathématique bien particulier, corrigé 0 (échec) et 1 (réussite) (variable artificiellement dichotomique), des trente-deux élèves. En utilisant la formule ci-dessus, il obtient :
rbis = + 0,60
3. Interprétation : Selon l’échelle de GUILFORD (VA A), il semble exister une relation positive et modérée entre les deux variables. Pour tester la signification de ce coefficient, le lecteur est invité à consulter des ouvrages spécialisés, notamment Gene V. GLASS et Kenneth D. HOPKINS (1984).
E. Coefficient de corrélation point bisérial : coefficient qui mesure le degré de relation entre une variable continue (Y) et une variable vraiment dichotomique (X).
1. Expression mathématique : On peut appliquer directement la formule du coefficient « r » de Bravais-Pearson (VA C) ou la formule équivalente suivante :
où : Y1 = moyenne à Y de ceux qui ont obtenu le score 1 à X
Y0 = moyenne à Y de ceux qui ont obtenu le score 0 à X
Sy = écart type de Y pour les n sujets
n1 = nombre de sujets qui ont obtenu 1 à la variable X
n0 = nombre de sujets qui ont obtenu 0 à la variable X
n = nombre total de sujets = n1 + n 0
2. Exemple : Considérer l’exemple donné en C. Ici, l’enseignant veut savoir s’il existe une corrélation entre le rendement scolaire (variable continue) et le sexe (variable dichotomique, féminin = 0; masculin = 1) des trente-deux élèves. Après calcul, il obtient : rpb = + 0,16
3. Interprétation : L’enseignant vérifie la signification statistique de cette valeur en utilisant la table des valeurs critiques de r, toujours pour n = 32 et α = 0,05. Puisque (rpb calculé = 0,16) < (r critique = 0,30, pour un test unilatéral), il n’existe donc pas de corrélation statistiquement significative au seuil de 0,05 entre le rendement scolaire et le sexe. Les garçons ont un aussi bon rendement scolaire que les filles et vice versa.
F. Coefficient de corrélation de rangs de Spearman : coefficient qui mesure le degré de relation entre deux variables constituées de rangs.
où :
di = RXi - RYi (différence entre le rang à la variable X et le rang à la variable Y pour le même sujet i)
n = nombre total de sujets
2. Exemple : Considérons l’exemple donné en C. Ici, l’enseignant décide de classer en ordre décroissant les élèves selon, dans un premier temps, leur rendement scolaire et, dans un deuxième temps, leur nombre d’heures d’étude par semaine. Il attribue ainsi pour chacun des trente-deux élèves un rang pour le rendement scolaire et un rang pour le nombre d’heures d’étude par semaine. En utilisant la formule ci-dessus, il obtient : rs = + 0,5
3. Interprétation : L’enseignant consulte la table des valeurs critiques de r puisque le nombre de sujets est plus grand que 30. (Pour un nombre de sujets égal ou inférieur à 30, on consulte la table des valeurs critiques de rs). Il constate que pour n = 32 et α = 0,05, le r critique vaut 0,30, pour un test unilatéral. La conclusion est donc similaire à celle obtenue en C.
G. Coefficient de corrélation tétrachorique : coefficient quimesure le degré de relation entre deux variables artificiellement dichotomiques.
où : a = nombre de sujets ayant la valeur 1 à la variable Y et 0 à la variable X
b = nombre de sujets ayant la valeur 1 aux deux variables
c = nombre de sujets ayant la valeur 0 aux deux variables
d = nombre de sujets ayant la valeur 0 à la variable Y et 1 à la variable X
uX = ordonnée de la distribution normale centrée réduite à pX (selon table appropriée)
uY = ordonnée de la distribution normale centrée réduite à pY (selon table appropriée)
pX = proportion de ceux qui ont la valeur 1 à la variable X = (b + d)/n
pY = proportion de ceux qui ont la valeur 1 à la variable Y = (b + a)/n
n = nombre total de sujets
Les données (scores et fréquences) sont habituellement entrées dans un tableau de contingence 2 X 2 :
Y
X
1
0
ou
Y
X
1
0
1
b
d
1
b
a
0
a
c
0
d
c
2. Exemple : Considérons les exemples donnés en C et D. Ici,
l’enseignant veut savoir s’il existe une relation entre la performance des
trente-deux élèves à deux items, un item de mathématique et un item de
français, corrigés 1 (réussite) et 0 autrement (échec ou omission). En
utilisant l’expression ci-dessus, l’enseignant obtient : rtet =
+ 0,75.
3. Interprétation : Il semble exister
une relation positive (forte selon l’échelle de GUILFORD) entre les scores
obtenus aux deux items. Dans l’ensemble, les élèves qui ont réussi l’item de
mathématique ont aussi réussi l’item de français et vice versa. Pour tester la
signification statistique de ce coefficient, le lecteur est invité à consulter
des ouvrages spécialisés, notamment G. V. GLASS et K. D. HOPKINS
(1984).
H. Coefficient phi : coefficient
quimesure le
degré de relation entre deux variables vraiment dichotomiques.
1. Expression
mathématique : On peut appliquer la formule du coefficient « r » de Bravais-Pearson (VA C) aux scores
dichotomiques des deux variables mises en relation. On peut aussi disposer ces
scores dichotomiques dans un tableau de contingence de 2 X 2 (VA G) et procéder
comme suit :
où :
a = nombre de sujets
ayant la valeur 1 à la variable Y et 0 à la variable X
b = nombre de sujets
ayant la valeur 1 aux deux variables
c = nombre de sujets
ayant la valeur 0 aux deux variables
d = nombre de sujets ayant la valeur 0 à la variable Y et 1 à la
variable X
2.
Exemple : Considérons l’exemple donné en C. Ici, l’enseignant désire
savoir s’il existe un lien entre le sexe et le fait de prendre ou non un petit
déjeuner. Les garçons sont classés (0) et les filles (1). De même, la prise
d’un petit déjeuner est notée (1) et l’absence d’un petit déjeuner (0).
Après calcul, l’enseignant obtient : rΦ = + 0,11
3. Interprétation : La signification
statistique de cette valeur est vérifiée grâce au test du χ2 (khi-deux)
où la valeur critique du χ2, pour un
seuil de signification de 0,05 et 1 degré de liberté, est de 3,8414. Si le χ2 calculé est
inférieur ou égal au χ2 critique alors la valeur de rΦ ne sera pas
statistiquement significative, l’enseignant conclura qu’il n’y a pas de lien ou
de relation entre le sexe et la prise ou non d’un petit déjeuner. Dans le cas
contraire, c’est-à-dire si le χ2 calculé est
supérieur au χ2 critique, on dira qu’il existe un lien entre ces deux variables.
V épreuve du
khi-deux.
I. Coefficient de corrélation multiple : coefficient qui mesure le degré de relation entre une variable
dépendante et deux ou plusieurs variables indépendantes. VA K.
1. Expression
mathématique :
a) pour le modèle à deux variables
indépendantes :
où : Y est la variable dépendante
1 et 2 sont les variables
indépendantes
b) pour le modèle à n variables
indépendantes :
le symbole du coefficient est RY,12...n;
l’expression étant très complexe, le lecteur est invité à consulter des
ouvrages spécialisés de statistiques.
2. Exemple avec deux variables
indépendantes : Un enseignant désire savoir si la performance en français
et l’intelligence (variables indépendantes) de ses élèves sont deux variables
qui influencent leur rendement en mathématique (variable dépendante). Après
avoir recueilli les résultats des trente élèves pour les trois variables
étudiées, l’enseignant calcule le coefficient de corrélation multiple et
obtient : RY,12 = 0,60.
3. Interprétation : Le test de
signification statistique de ce coefficient étant assez complexe, là encore le
lecteur est invité à consulter des ouvrages spécialisés de statistiques. Si le
coefficient est statistiquement significatif, on peut dire que les deux
variables indépendantes permettent de prédire la variable dépendante.
J. Coefficient de corrélation partielle : coefficient qui mesure le degré de relation linéaire entre deux
variables quand l’effet d’une ou de plusieurs autres variables est maintenu
constant ou annulé. Les coefficients de corrélation partielle les plus souvent
utilisés sont les coefficients de corrélation partielle d’ordre un et d’ordre
deux.
1. Expression mathématique :
a) pour le coefficient de corrélation partielle
d’ordre un (l’effet d’une variable est maintenu constant ou annulé)
où :1
: première variable
2 : deuxième variable
0,3 : troisième variable (dont
l’effet sur chacune des variables 1 et 2 est ici annulé)
r12 : coefficient
de corrélation de Bravais-Pearson
entre les première et deuxième variables
r13 : coefficient
de corrélation de Bravais-Pearson
entre les première et troisième variables
r23 : coefficient
de corrélation de Bravais-Pearson
entre les deuxième et troisième variables
b) pour
le coefficient de corrélation partielle d’ordre deux (l’effet de deux variables
est maintenu constant ou annulé)
où :1 : première variable
2 : deuxième variable
0,34 : troisième et quatrième
variables (dont l’effet sur chacune des variables 1 et 2 est ici annulé)
r12,3 : coefficient
de corrélation partielle entre les première et deuxième variables quand l’effet
de la troisième variable est ici annulé
r14,3 : coefficient
de corrélation partielle entre les première et quatrième variables quand
l’effet de la troisième variable est ici annulé
r24,3 : coefficient
de corrélation partielle entre les deuxième et quatrième variables quand
l’effet de la troisième variable est ici annulé
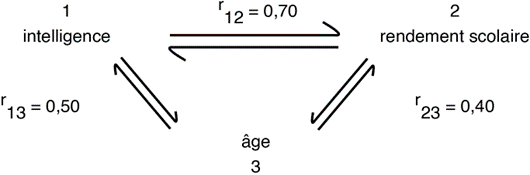
2. Exemple : Le directeur d’une école
primaire veut déterminer s’il existe une corrélation entre l’intelligence et le
rendement scolaire de ses élèves du second cycle. Mais, puisqu’il soupçonne une
corrélation possible entre l’âge et ces deux variables (corrélation qui
pourrait influencer le degré de relation réel entre l’intelligence et le
rendement scolaire), il utilisera le coefficient de corrélation partielle.
Après calcul, le directeur obtient les valeurs suivantes :
3.
Interprétation : Même interprétation que pour le coefficient de
corrélation de Bravais-Pearson.
De plus, le directeur peut comparer r12 et r12,3 pour
voir l’influence de l’âge sur la corrélation entre l’intelligence et le
rendement scolaire.
4. Remarque : Le directeur pourrait
également stabiliser la variable âge en ne prenant que des élèves du même âge
pour son étude. Toutefois, cela demeure difficile à réaliser, car rares sont
les enfants qui ont exactement le même âge.
K. Corrélation simple/multiple/partielle. Lorsque plusieurs variables semblent intervenir sur une variable cible
dépendante dans le cadre d’un phénomène, il peut être utile de calculer les
trois types de coefficient de corrélation en titre. C’est ce que firent
Benjamin S. BLOOM et ses collaborateurs qui ont maintes fois calculé les
diverses relations qui pouvaient exister entre le quotient intellectuel (QI)
d’un élève, ses préalables (P) ainsi que son rendement scolaire (RS). Le
tableau suivant donne la valeur moyenne des coefficients obtenus en tenant
compte des données de milliers d’élèves à tous les ordres d’enseignement et
dans une diversité d’objectifs d’apprentissage.
SIMPLE
PARTIELLE
MULTIPLE
QI et RS → r = 0,50
corrélation modérée
(QI et RS) - P → r = 0,30
baisse de 0,20 : corrélation
faible
P
et RS → r = 0,80
corrélation forte
(P
et RS) - QI → r = 0,70
baisse de 0,10 : corrélation
forte
(P et RS) + QI → r = 0,85
hausse de 0,05 : corrélation
forte
Par une telle analyse, BLOOM a démontré le faible impact du QI sur
le rendement scolaire. Par les corrélations partielles et multiples, il s’est
aperçu que le fait de soustraire ou d’ajouter le QI aux préalables ne fait pas
varier significativement la corrélation déjà forte qui existe entre les
préalables d’un élève et son rendement scolaire. Ainsi, lorsque l’on soustrait
l’effet des préalables (P) des variables quotient intellectuel (QI) et
rendement scolaire (RS), la corrélation simple de 0,50 qui existe entre ces
deux variables chute alors à 0,30 (corrélation partielle), ce qui est une
corrélation faible. Par contre, si l’on soustrait l’effet du quotient intellectuel
(QI) des variables préalables (P) et rendement scolaire (RS), la corrélation
partielle est de 0,70 alors que la corrélation simple entre les variables
préalables (P) et rendement scolaire (RS) est de 0,80. La corrélation chute de
0,80 à 0,70 mais elle se maintient néanmoins forte si on enlève l’effet du QI
Si, à la corrélation simple, on ajoute l’impact du QI, le coefficient déjà
significativement élevé de 0,80 indiquant la forte relation des préalables P
sur le rendement scolaire RS, ne s’élève alors que de 0,05 à une valeur de 0,85
en corrélation multiple.
L. Coefficient de contingence : coefficient
quimesure le
degré de relation ou d’association entre deux variables possédant deux ou
plusieurs catégories. À cause de ses limites, ce coefficient est maintenant peu
utilisé en faveur du coefficient V de CRAMER (VA M).
Expression mathématique :
où : χ2 : la
valeur du χ2 calculée à partir des fréquences observées et théoriques de
chaque catégorie. V épreuve du khi-deux.
n : nombre total de sujets
M. Coefficient de CRAMER : coefficient qui mesure le degré
de relation ou d’association entre deux variables possédant deux ou plusieurs
catégories.
1. Expression
mathématique :
où χ2 : la valeur du χ2 calculée à
partir des fréquences observées et théoriques de chaque catégorie. V épreuve du
khi-deux.
n : nombre total de sujets
L : nombre minimal de rangées ou de colonnes dans
le tableau de contingence
2. Interprétation et limites : La
valeur de V est 0 lorsqu’il y a absence de toute relation entre les variables,
mais la valeur de V peut être égale à 1 même s’il n’existe pas une relation
parfaite entre les deux variables concernées. Cette situation peut se produire
lorsqu’on a un tableau de contingence pour lequel le nombre de rangées est
différent du nombre de colonnes. Le coefficient de CRAMER possède toutefois un
avantage par rapport au coefficient de contingence. En effet, on peut comparer
les coefficients de CRAMER obtenus de tableaux de contingence de différentes
dimensions, ce qu’on ne peut pas faire avec le coefficient de contingence. On
notera aussi que V ne peut être calculé que pour des données pour lesquelles χ2 peut l’être,
c’est-à-dire seulement si moins de 20 % des cases du tableau de
contingence ont une fréquence théorique inférieure à 5 et qu’aucune case n’a
une fréquence théorique inférieure à 1.
3. Exemple : Pour
l’épreuve du khi-deux où χ2 = 1,90 avec
L = 2 et n= 100, on a V = 0,14. Ce coefficient indique une association faible.
C’est l’épreuve du khi-deux qui indique la signification statistique de cette
relation. Selon cet exemple, l’épreuve du khi-deux (test du χ2) démontre
que cette association n’est pas statistiquement significative au seuil de 0,05.